Introduction
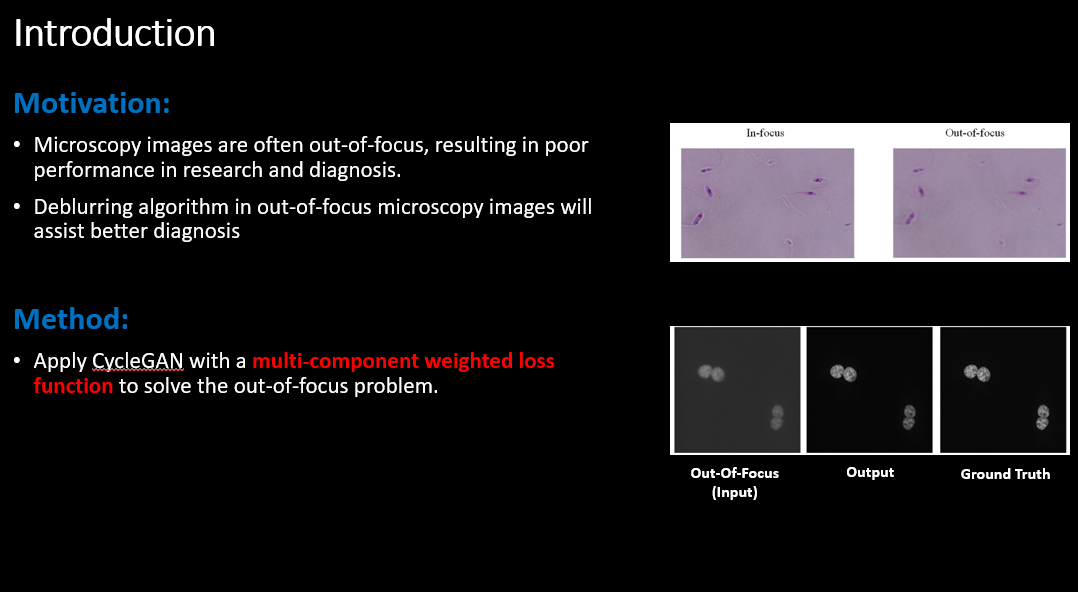
Motivation
현미경으로 얻은 Microscopy images 는 촬영 환경이나 초점 세팅의 한계로 인해 자주 out-of-focus 상태로 기록된다. 이렇게 초점이 맞지 않은 이미지는 세포 구조나 조직 경계를 흐릿하게 만들어, 연구 및 진단에서 성능 저하를 일으킨다.
특히 임상·연구 환경에서는 동일 샘플을 다시 촬영하기 어려운 경우가 많기 때문에, 이미 촬영된 out-of-focus Microscopy images 를 in-focus 수준으로 복원하는 Deblurring 알고리즘의 필요성이 크다.
Method
이 논문은 이미지 도메인 변환에 널리 사용되는 CycleGAN 구조를 기반으로, out-of-focus Microscopy images 를 in-focus 스타일의 이미지로 변환하는 Deblurring 네트워크를 제안한다.
이를 위해 단일 손실이 아니라 여러 손실 항으로 구성된 multi-component weighted loss function 을 도입하여, 단순히 이미지를 선명하게 만드는 것을 넘어 구조 보존과 텍스처 유지, 그리고 Ground Truth in-focus 이미지 와의 전반적인 시각적 일관성을 동시에 향상시키는 것을 목표로 한다.
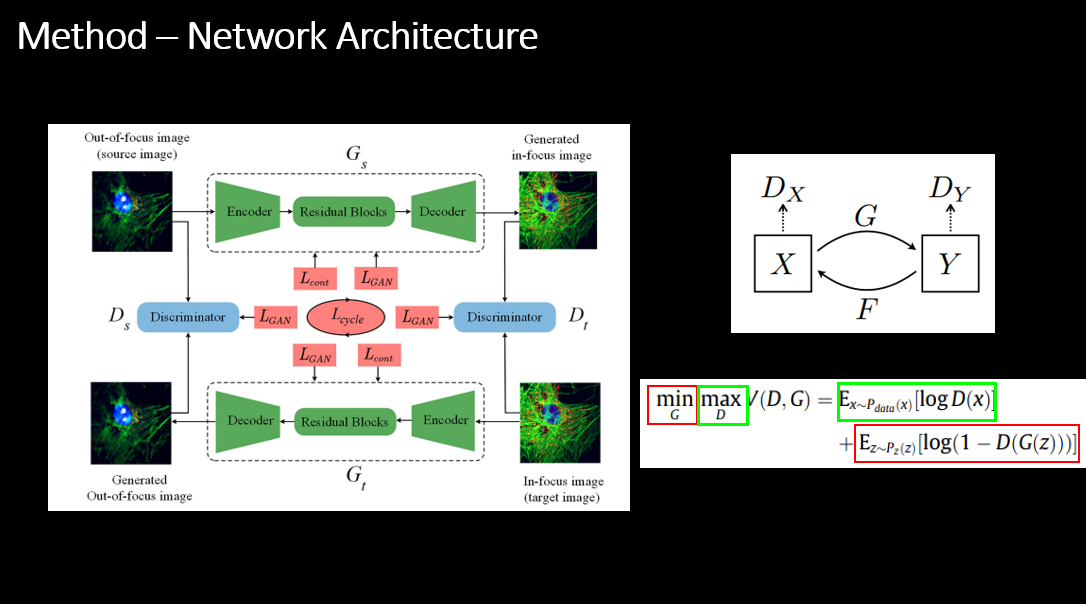
Method – Network Architecture
이 논문은 두 도메인 사이의 Image-to-Image Translation 을 수행하는 CycleGAN 구조를 기반으로 한다. 여기서 Source 도메인은 out-of-focus Microscopy image 이고, Target 도메인은 in-focus Microscopy image 이다.
이를 위해 두 개의 Generator, Gs : Source → Target 와 Gt : Target → Source 를 사용한다. 각 Generator는 Encoder – Residual Blocks – Decoder 구조로 되어 있어, Encoder에서 이미지를 feature 공간으로 압축하고, Residual Blocks에서 복잡한 패턴과 컨텍스트를 학습한 뒤, Decoder에서 다시 이미지 공간으로 복원한다.
각 도메인에는 별도의 Discriminator Ds, Dt 를 두어 생성된 이미지가 해당 도메인의 real image 처럼 보이는지 판단한다. 즉, G 는 D 를 속이도록 이미지를 생성하고, D 는 real / fake 를 구분하도록 학습되는 전형적인 Adversarial learning 구조이다.

Method – Multi-Component Weighted Loss
전체 학습은 하나의 손실이 아니라, 세 가지 손실을 합친 multi-component weighted loss function 으로 이루어진다:
1) LGAN : 각 도메인 Discriminator(Ds, Dt) 를 이용해 생성 이미지가 real in-focus / out-of-focus image 처럼 보이도록 만드는 Adversarial loss 이다. 쉽게 말하면, “진짜처럼 보이게 만드는 손실” 이다.
2) Lcont (content loss): 사전학습된 네트워크의 feature space 에서 생성 이미지와 Ground Truth 이미지의 특징을 비교하여, 구조(structure)와 텍스처(texture) 를 보존하도록 유도하는 손실이다. 논문에서는 Gs, Gt 양 방향에 대해 content loss 를 계산하고 더해, 세포 모양과 세부 구조가 무너지지 않도록 제어한다.
3) Lcycle (cycle-consistency loss): out-of-focus 이미지를 Gs 로 in-focus 로 보냈다가, 다시 Gt 로 원래 도메인으로 되돌렸을 때, 입력 이미지와 크게 달라지지 않도록 pixel-wise 차이를 줄이는 손실이다. 이는 Cycle consistency 를 보장하여 비현실적인 변환이나 모드 붕괴를 방지한다.
최종 학습 목표는 세 손실을 가중합한 L = λ1LGAN + λ2Lcont + λ3Lcycle 이며, 각 λ 값은 각각 “얼마나 진짜처럼 보일지”, “얼마나 구조·텍스처를 보존할지”, “얼마나 변환 전·후를 일관되게 유지할지” 의 비중을 조절하는 하이퍼파라미터로 볼 수 있다.
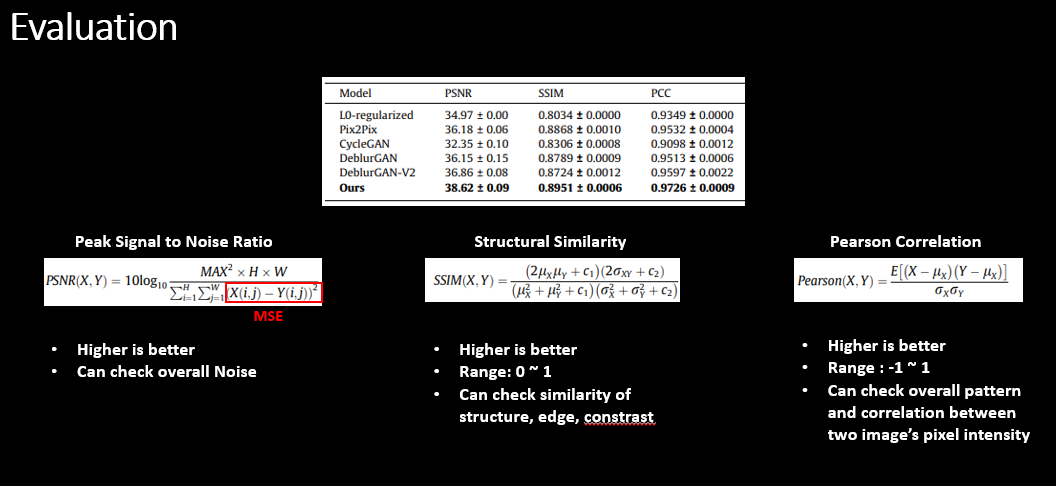
Evaluation
이 논문에서는 제안한 Deblurring CycleGAN 의 성능을 정량적으로 평가하기 위해 세 가지 대표적인 화질 지표를 사용한다: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Pearson Correlation Coefficient (PCC).
각 지표는 복원된 in-focus 이미지가 Ground Truth in-focus 이미지와 얼마나 비슷한지를 서로 다른 관점에서 측정한다. 모든 지표에서 값이 클수록 “더 좋은 복원 결과”를 의미한다.
Peak Signal-to-Noise Ratio (PSNR)
PSNR 은 이미지의 전반적인 노이즈 수준을 보는 지표로, 원본 신호 에너지에 비해 복원 오차(MSE)가 얼마나 작은지를 로그 스케일로 표현한다. 값이 클수록 노이즈가 적고, 픽셀 단위 오차가 작다는 뜻이다.
Structural Similarity Index (SSIM)
SSIM 은 단순한 픽셀 차이보다, 구조(structure), 에지(edge), 콘트라스트(contrast) 가 얼마나 잘 보존되었는지를 측정하는 지표이다. 범위는 보통 0 ~ 1이고, 1에 가까울수록 원본과 구조적으로 매우 유사한 이미지라고 해석할 수 있다.
Pearson Correlation Coefficient (PCC)
PCC 는 두 이미지의 픽셀 intensity 분포가 얼마나 비슷하게 움직이는지를 보는 상관계수이다. 범위는 -1 ~ 1이며, 1에 가까울수록 “밝을 때 같이 밝고, 어두울 때 같이 어두운” 패턴을 잘 유지한다는 의미이다.
실험 결과, 제안한 방법은 기존 Pix2Pix, CycleGAN, DeblurGAN 계열보다 PSNR, SSIM, PCC 모두에서 더 높은 값을 기록하여, 노이즈 억제뿐 아니라 구조·텍스처 보존과 전체적인 패턴 일치 측면에서도 우수한 in-focus 복원 성능을 보여준다.

Result – Comparison with Existing Methods
첫 번째 결과 그림은 out-of-focus 이미지를 입력으로 했을 때, L0-regularized, Pix2Pix, CycleGAN, DeblurGAN, DeblurGAN-V2 그리고 제안 방법(Ours) 이 어떤 출력을 내는지 시각적으로 비교한 예시이다.
파란색/빨간색 박스로 표시된 국소 영역을 보면, 기존 방법들은 세포 모양이 흐려지거나, 경계가 과도하게 날카로워지는 등 노이즈 또는 구조 왜곡이 남아 있는 반면, Ours는 in-focus 이미지와 가까운 형태로 세포의 윤곽과 내부 텍스처를 더 잘 복원함을 확인할 수 있다.
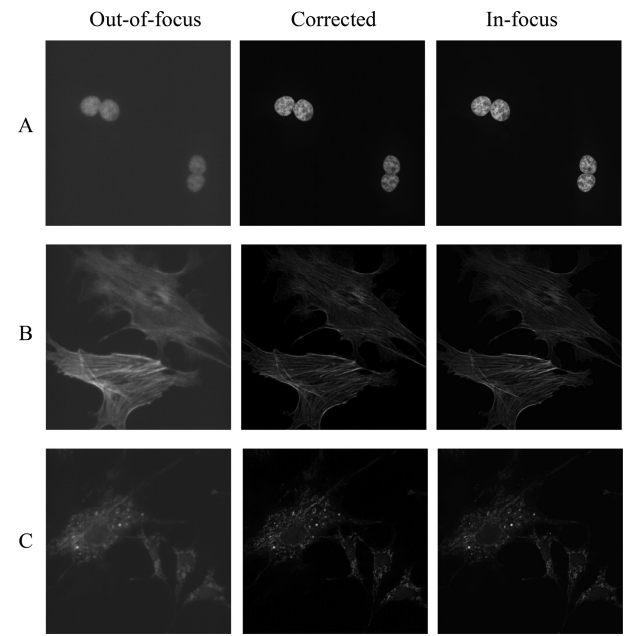
Result – Out-of-focus → Corrected → In-focus
두 번째 그림은 서로 다른 샘플(A, B, C)에 대해 Out-of-focus, Corrected(제안 모델 출력), In-focus 를 한 줄에서 비교한 결과이다.
각 샘플에서 Corrected 이미지는 원래 out-of-focus 이미지보다 명확한 에지와 세포 구조를 보여주며, 밝기와 콘트라스트도 Ground Truth in-focus 에 가깝게 맞춰져 있다. 특히 세포 내부의 세밀한 패턴이나 필라멘트 구조가 다시 드러나는 것을 통해 제안 모델이 단순 샤프닝이 아니라 구조 복원을 수행한다는 점을 알 수 있다.
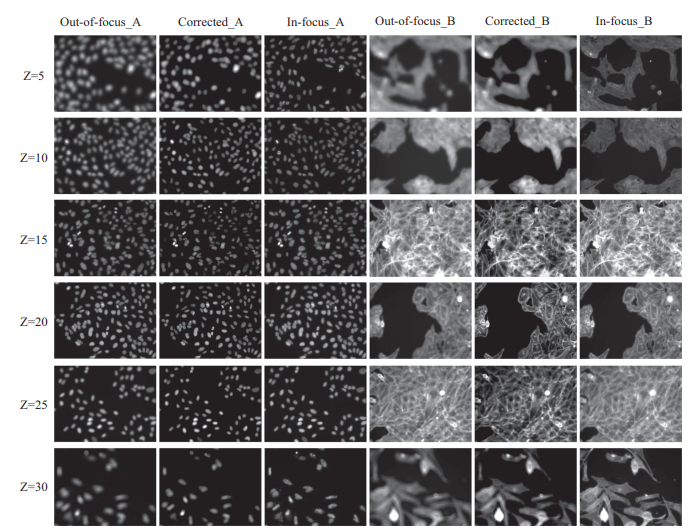
Result – Z-stack Across Multiple Depths
세 번째 그림은 서로 다른 Z-depth(Z=5~30) 에서 획득한 Out-of-focus_A/B, 제안 모델의 Corrected_A/B, 그리고 In-focus_A/B 를 함께 보여주는 Z-stack 결과이다.
Z가 깊어질수록 원본 out-of-focus 이미지는 점점 더 흐려지고 세포 경계가 사라지지만, 제안된 Corrected 결과는 각 Z에서 in-focus 이미지와 유사한 구조·패턴을 유지하고 있다. 이는 본 모델이 단일 깊이에 국한되지 않고, 여러 초점 깊이에서 일관된 deblurring 성능을 낸다는 것을 보여준다.
정리하면, 시각적 결과와 정량적 지표(PSNR, SSIM, PCC)를 종합했을 때 제안한 Deblurring CycleGAN with multi-component weighted loss 는 기존 방법들보다 구조 보존, 노이즈 억제, 시각적 일관성 측면에서 더 우수한 out-of-focus 보정 성능을 달성한다.
Conclusion
이 논문은 out-of-focus Microscopy image 를 in-focus image 로 복원하기 위한 Deblurring 네트워크를 제안한다. 구조적으로는 CycleGAN 과 유사한 두 개의 Generator–Discriminator 구성을 사용하지만, 학습 데이터는 unpaired dataset 이 아니라 paired out-of-focus / in-focus dataset 이라는 점이 핵심적인 차이이다.
즉, Pix2Pix 처럼 정답 in-focus 이미지를 직접 참조하면서 학습하되, CycleGAN-style 의 cycle-consistency 와 feature space content loss, 그리고 GAN loss 를 함께 사용하는 multi-component weighted loss function 으로 구조 보존, 텍스처 복원, 시각적 자연스러움을 동시에 최적화한다.
정량 지표(PSNR, SSIM, PCC)와 시각적 비교 결과에서 제안 방법은 기존 Pix2Pix, CycleGAN, DeblurGAN 계열보다 더 높은 성능을 보이며, 다양한 샘플과 여러 Z-depth 에서 일관된 in-focus 복원 품질을 달성한다. 따라서 이 모델은 out-of-focus 문제가 빈번한 현미경 영상에서 연구·진단의 신뢰도를 높이는 practical한 Deblurring 솔루션으로 볼 수 있다.