
왜 이 논문을 선택했는가?
기존 CycleGAN 계열 모델은 내가 원하는 부분만 바꾸기보다 이미지 전체가 함께 변형되는 문제가 있었다. 현재 현미경 영상에서 세포(cell) 영역을 향상(Enhancement)하는 연구를 진행 중인 필자는, 변환 과정에서 세포 이외의 배경까지 함께 바뀌는 현상을 최소화하고자 했다.
이 논문의 핵심은 간단하다. 어텐션 맵(attention map)을 학습해 변환이 필요한 영역만 선택적으로 바꾸고, 배경은 최대한 보존하는 것이다.
그 결과, 더 자연스럽고 의미(구조) 보존이 잘 되는 번역 이미지를 얻을 수 있다.
이제부터 본 논문의 아이디어와 방법을 조금 더 자세히 살펴보자.
Background

Image-to-Image Translation : 한 도메인의 이미지를 다른 도메인으로 변환하는 것.
핵심은 내용/구조는 유지하면서 스타일/도메인만 변경하는 것이다.
문제는, CycleGAN처럼 전체 이미지를 다루면 배경, 조명, 텍스처까지 바뀌어 구조 보존이 어려울 수 있다는 것이다.

이전 모델(CycleGAN)의 한계는 전체를 바꾼다는 것.
즉, 우리가 원하는 관심 부분(ROI)만 변경하는 것이 아닌, 불필요한 background도 함께 변환하는 것이다.
따라서 이 논문의 핵심 아이디어는 다음과 같다.
“Translation Network가 어디를 바꿔야 하는지(foreground),
어디는 유지해야 하는지(background)를 스스로 Attention Map으로 학습하게 만들자”

Method - Overview
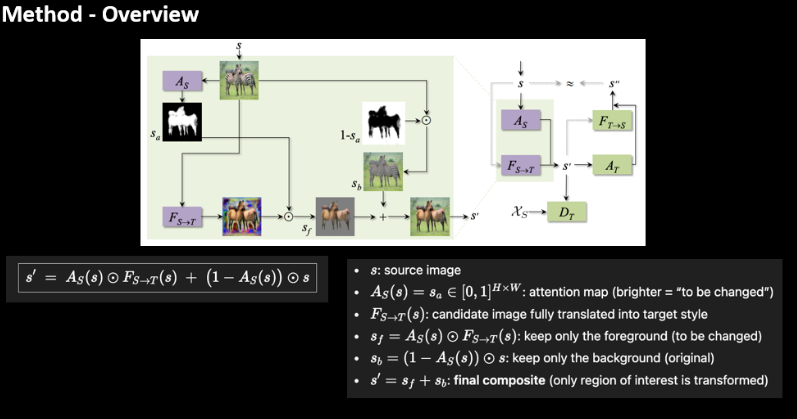
전체 구조는 다음과 같습니다. CycleGAN과 마찬가지로 양방향 생성기로,
\(F_{S \rightarrow T}, F_{T \rightarrow S}\) 로 구성된다.
Attention Network는 입력마다 \(A_S(s), A_T(t)\) 라는 soft attention map을 0~1 사이로 예측한다.
Discriminator는 \(D_T, D_S\) 로 구성되며, 주의 영역만 보도록 입력을 마스킹한다.
이 때, 최종 output은 foreground와 background를 합친 값이다.
Attention-guided Generator
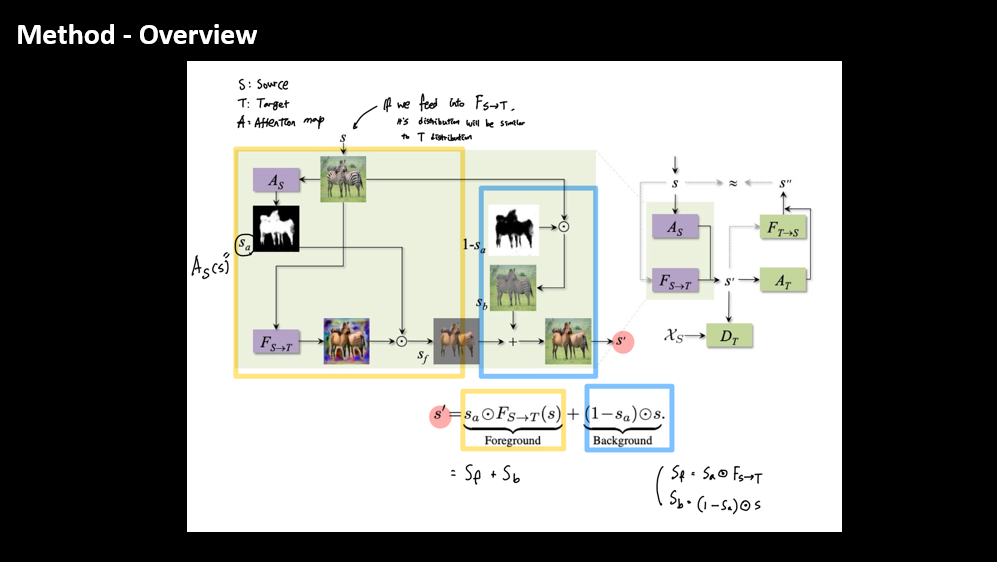
Generator는 \(A_S(s)\) 라는 0과 1 사이 값으로 구성된 가중치 맵을 배운다.
이 가중치 맵을 보고 변환할지, 그대로 둘지 결정한다.
예를 들어, \(A_S = 1\) 이면 변환을 채택, \(A_S = 0\) 이면 원본을 유지한다.
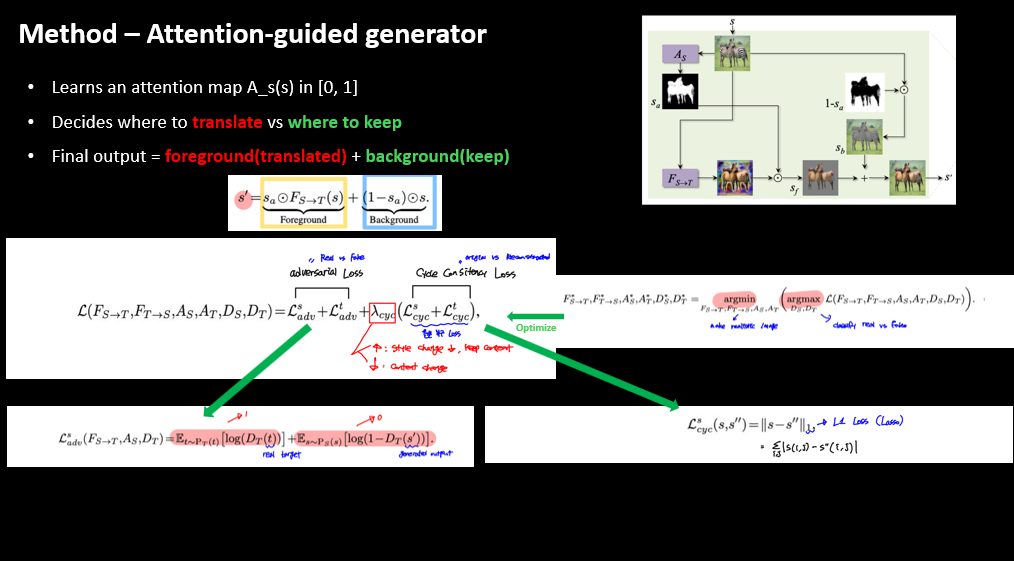
Loss Function은 Adversarial Loss와 Cycle Consistency Loss로 구성된다.
Adversarial Loss는 진짜/가짜를 구별하고, Cycle Consistency Loss는 원본과 생성된 이미지의 차이를 줄인다.
Cycle Consistency의 가중치(람다)가 커지면 내용 보존이 강해지고, 작아지면 내용 변화가 커질 위험이 있다. (논문에서는 $ \lambda =10 사용)
Adversarial Loss에서 real target 이미지는 1로, 생성 이미지는 0으로 판별하도록 학습한다.
Cycle Consistency Loss는 L1로 원본과 생성물의 차이를 줄여 더 진짜 같은 이미지를 만들도록 유도한다.
두 손실을 합친 최종 목적함수는 GAN의 minimax로 풀며, 생성기/어텐션은 minimize, 판별기는 maximize한다.
Attention-guided Discriminator
Discriminator가 전체 이미지를 보면 배경 통계를 학습해 Generator가 배경까지 변환하는 현상이 생길 수 있다.
이를 막기 위해 Attention 값이 높은 영역만 보도록 입력을 마스킹한다.
먼저 threshold 값을 사용하여 입력 마스크를 만들고(논문에선 0.1),
마스킹된 영역에만 Adversarial Loss를 계산한다.
학습 주의사항: 초기 attention map은 랜덤에 가깝기 때문에, 처음부터 마스킹하면 틀린 영역을 강화할 수 있다. 따라서 초기(약 0–30 epoch)에는 전체 이미지를 사용해 판별기를 안정화시키며 attention이 형성되도록 한다. 이후 epoch 30 이후에는 threshold로 이진화한 attention mask를 적용한다.
Results

결과적으로 CycleGAN 등 기존 모델보다, 우리가 원하는 ROI 부분만 선택적으로 변경되는 모습을 확인할 수 있다.